
Automatically optimize CUDA kernels for peak performance.
Free
Automatically optimize CUDA kernels for peak performance.
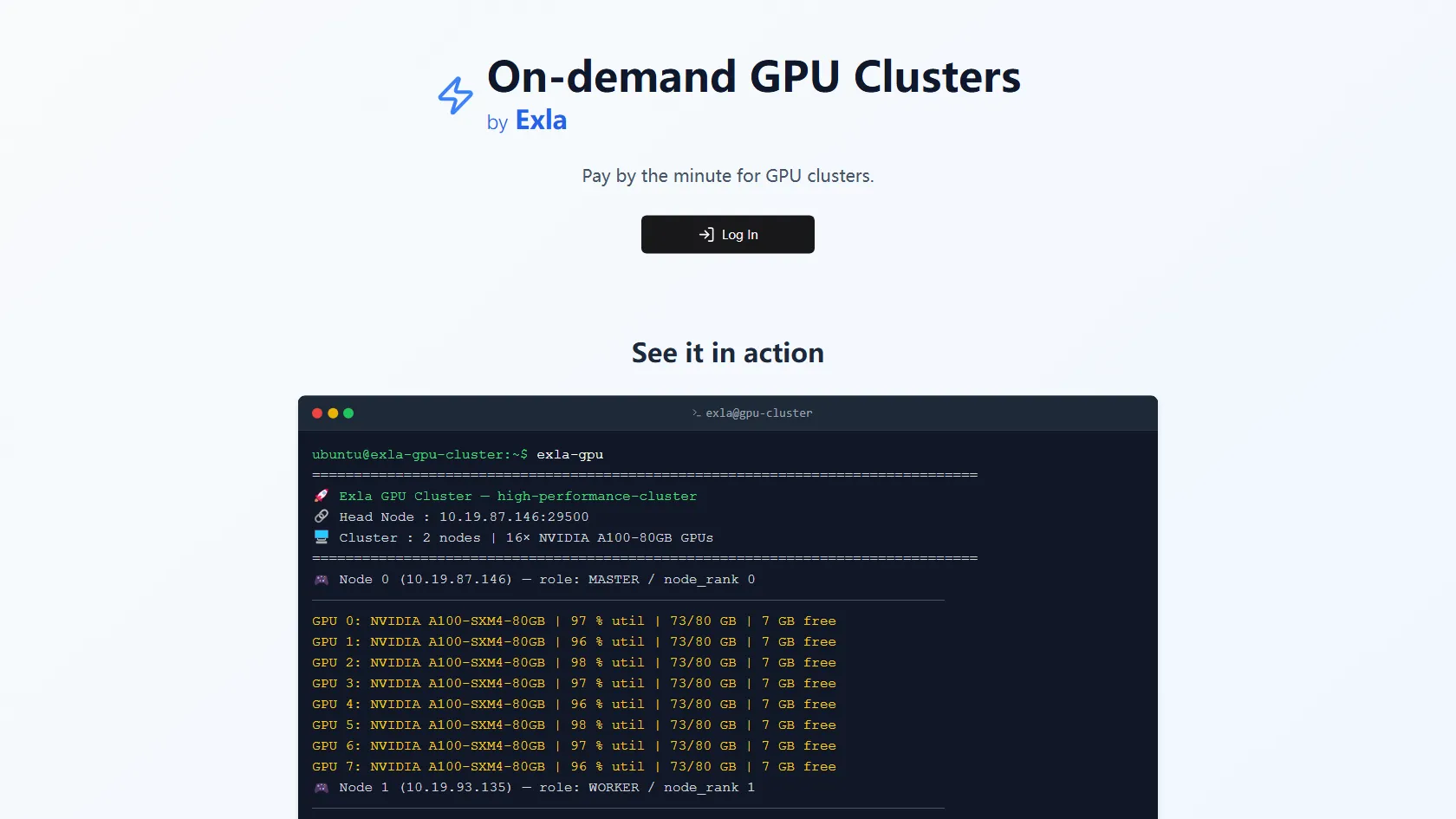
Launch distributed training clusters with H100, A100, and more GPUs in seconds.

Deploy machine learning models on serverless GPUs in minutes.